@SJCooper
Thanks again for the FOI link. The two listings they provided are a major update on those from the regular URLs and I was able to add my postcode data by pasting the stop map references into an online Batch Postcode Finder.
The person that made the FoI request was hoping that it might prompt the two files you mentioned to be updated but sadly not. Maybe he’ll just re-submit the FoI request on a monthly basis to keep getting updates…
I use the Naptan data to augment the TfL stop data but they are not an alternative. Only TfL provide the route (sequence) listing. Only the TfL stop listing identifies all stops covered by TfL whilst excluding all others.
@briantist
Do you know an easy way to transform hundreds of XML files in four zip files into a single csv stop database and a single csv sequence (route) database like those discussed above?
I produce a text file of stop sequences served once a week from the zip files within Excel using VBA. I vaguely remember posting about this but nobody seemed terribly interested! As the code runs automatically within a more comprehensive data extraction process the stop sequence files are still being produced.
Here are the first few lines
267;21_61830;12/08/2023;New file;1;490007705C;O;1;Hammersmith Bus Station;Hammersmith Bus Station;523395;178522
267;21_61830;12/08/2023;New file;2;490008801P;O;2;Livat Hammersmith Shopping Centre;Livat Hammersmith Shopping Centre;523175;178561
267;21_61830;12/08/2023;New file;3;490007711WA;O;3;Hammersmith Town Hall;Hammersmith Town Hall;522778;178543
267;21_61830;12/08/2023;New file;4;490011594W;O;4;Ravenscourt Park Station;Ravenscourt Park Station;522571;178581
267;21_61830;12/08/2023;New file;5;490012533W;O;5;Ravenscourt Park;Ravenscourt Park;522251;178636
267;21_61830;12/08/2023;New file;6;490007272H;O;6;Goldhawk Road (W6);Goldhawk Road (W6);521996;178621
The fields are:-
i) route
ii) operator and pseudo-Service Change Number (pseudo because they no longer match the real SCNs as shown on Working Timetables)
iii) date timetable starts (to be ignored unless in the future)
iv) whether a new file, no change or a metadata revision for an existing stop
v) order in stop sequence
vi) ATCO code (usually 499…)
vii) inbound or outbound
viii) order in stop sequence (again! - I this is done a different way to help track down inconsistencies but I can’t remember off the top of my head)
ix) “CommonName” for stop
x) “Notes” for stop (usually same as CommonName)
xi) easting
xii) northing
This would be easy to import into a database. Because it gives stop sequences there is wholesale duplication of stops but it would be easy enough to ignore unwanted fields and not allowing duplicates. There may also be issues if the stop sequence is corrupted in some way, which happens every few weeks to the odd file. This week’s version is clean however.
@mjcarchive
Is the link a one-off post or do you update it regularly?
I have had a quick play with the file and can easily extract and augment the key fields to convert it to my regular routes (sequences) database. They change much more frequently than the basic stop data so a regular update would be really useful. And much easier for me than trying to work out how handle the zip timetables!
Thanks.
PS
Forgot to mention that in column vii every entry is O. I assume they should be I or O?
@misar They should indeed. I’ll check in the next couple of days. I think I can do a deduped version easily enough too, which would just be a stops list. Also it ought to be fairly easy for me to identify new stops within the files and stops no longer there.
@misar I’m not going to produce a file this week as I’d rather get the process properly automated and working properly than do it ad hoc.
My thinking is to provide the stop sequences and stops as Excel rather than text files. In part to get round the issue that it is all too easy to import ATCO codes ending in an E, E2 etc. as involving exponentiation; if I can avoid that by doing an import into Excel myself then nobody else will have the opportunity to accidentally mess it up!
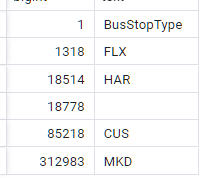
For what it is worth, there is one genuinely new stop this week, 490000169ZA is a new (additional) northbound stop at Old Street Station, served from 19th August (according to the files) by 21 43 76 141 and 214, with N271 probably still to come. Two further stops are reinstated - 490006443Z and 490012727Y - following the end of a southbound diversion on 192 around Edmonton Green.
@mjcarchive I converted your previous .txt file to .csv because I need .csv to use as a database. Also using Excel is essential for manipulating the data. Import the data setting the ATCO column as text instead of general. Providing them as .xlsx avoids the ATCO codes issue but .csv is simple and universal.
If you want to save to .csv for download here are a couple of ways to avoid problems.
Insert ’ in front of each ATCO code (needs a formula in my version of Excel). That field will then always remain as text even if the .csv is opened directly in Excel. I keep the ’ permanently for safety and strip it out when loading the database into my program but it is easily removed in Excel.
TfL sometimes insert a comma in a field (e.g. Guy, Earl of Warwick) which in a .csv appears as two fields. Therefore strip out commas before saving as .csv.
PS
Looking at your .txt download again I realised that you were ahead of me and replaced all the commas with _.
Also you mentioned the similarity between the Name and Notes columns. I now see that Names has many commas but Notes omits them, e.g.
Wolsey Avenue_ Walthamstow and Wolsey Avenue Walthamstow
It would be interesting to know what logic at TfL lies behind this!
Top tip: As per the CSV format’s specification, you can wrap strings containing commas with double quotes and it will be treated as a single field. For example, you can do something like:
id,commonName
490G00007611,"Guy, Earl of Warwick"
This should load correctly in most software that can read CSV files (including Excel). And most CSV-writing libraries will automatically surround fields containing commas with double quotes.
@LeonByford True, but your .csv downloads do not wrap those fields in double quotes. Also using “Guy, Earl of Warwick” as an example, I noticed that the NaPTAN .csv downloads omit the comma.
Apologies.
I checked back to the original downloads and you do insert double quotes. However, for some .csv uses other than a spreadsheet the policy of omitting commas makes life easier.
@misar and all
Thanks for advice. The file I did last week was essentially a by-product of something I set up a fair time ago and I need to refresh my memory of what it is doing (which is why I’m going to sort out a repeatable and properly documented process rather than just do it again).
My files are generated by Excel VBA. It makes a difference whether you Print or Write to a text file, one of the differences being the way double quotes are used. I may need to switch from one to t’other but that’s easy to change.
The “text treated as number” thing first came up for me when importing TfL’s own stops csv file. It took me longer than it should have to realise that the very large numbers I was getting in Croydon, Sutton and Kingston were bogus and arose from the use of suffices as high as E14!
I haven’t got time right now to refresh the files but I can report that there are two new stops in this week’s Datastore files, namely 490005800PW and 490005800RC. Both appear to be temporary stops for use while Cromwell Road Bus Station in Kingston is closed.
@mjcarchive
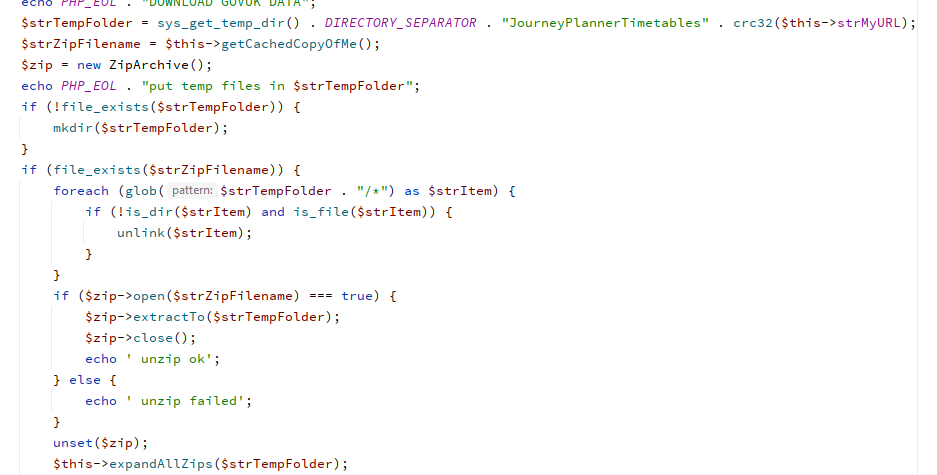
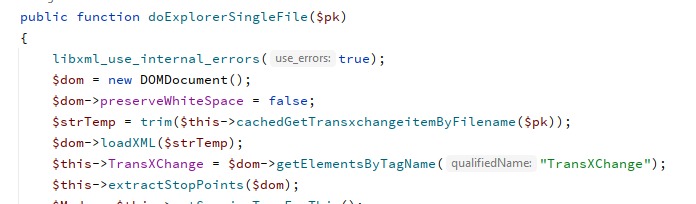
No problem. I decided to investigate using the XMLs to prepare a bus sequence CSV and adopted a program approach similar to @briantist rather than the Excel route. My app writes a bus sequence CSV from 781 XML files in about 10 sec but it also revealed some odd stats about the XML files.
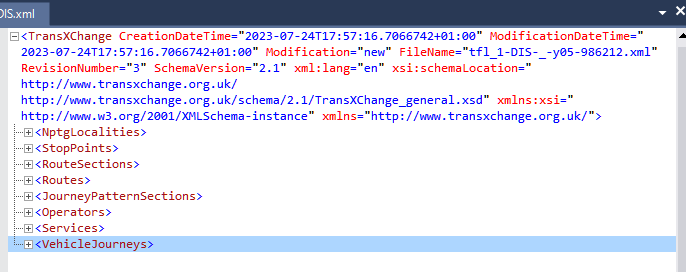
I only require a small part of the data in the files and after inspecting a few decided to use RouteLink blocks to obtain the route sequence and StopPoint blocks to augment their stop data. This seems to be a correct assumption for many routes with the number of inbound + outbound entries in the sequence about the same as the number of StopPoints. However, with many other routes the number of sequence entries is far too large and in some cases it is ridiculous. Some stops have two or more XMLs and sometimes only one of those looks anomalous. For example:
Route 71 has 68 StopPoints and 67 RouteLinks.
Route 115 has 77 StopPoints and 113 RouteLinks.
Route 123 has 113 StopPoints and 111 RouteLinks.
Route 123 has 113 StopPoints and 221 RouteLinks.
Route 224 has 63 StopPoints and 2661 RouteLinks.
Route 243 has 122 StopPoints and 235 RouteLinks.
Route 243 has 126 StopPoints and 12099 RouteLinks.
Route 57 has 122 StopPoints and 358 RouteLinks.
Route 57 has 121 StopPoints and 21421 RouteLinks.
The anomaly also explains the enormous variation in XML file size, from 22KB (685) to 30MB (57).
Any thoughts on the reason for the anomalies and, more importantly, how to extract an accurate sequence for every route?