I use the Naptan data to augment the TfL stop data but they are not an alternative. Only TfL provide the route (sequence) listing. Only the TfL stop listing identifies all stops covered by TfL whilst excluding all others.
@misar Well see How to get all bus stop stations in London? please
https://tfl.gov.uk/tfl/syndication/feeds/journey-planner-timetables.zip as I said has the sequences.
@briantist
Do you know an easy way to transform hundreds of XML files in four zip files into a single csv stop database and a single csv sequence (route) database like those discussed above?
In PHP I’m just using ZipArchive to get the files from the ZIP archive PHP: Examples - Manual
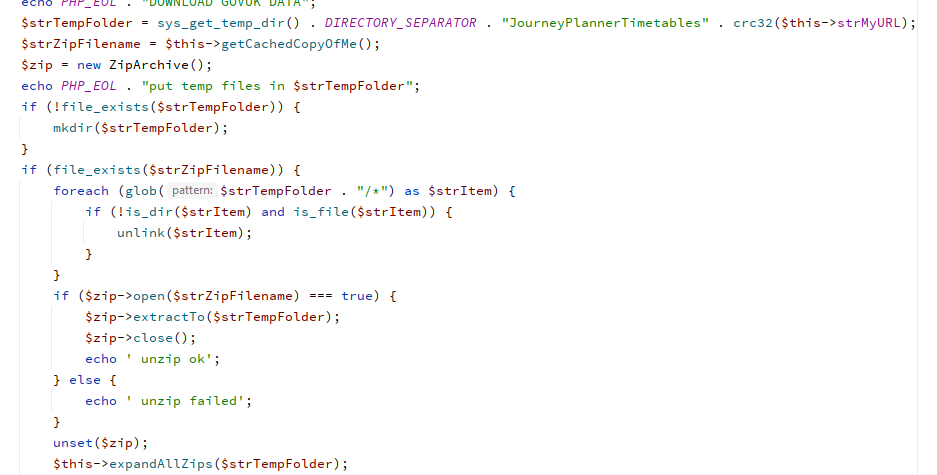
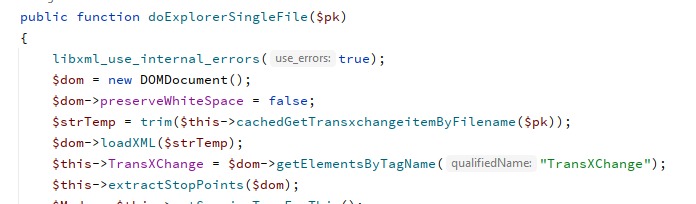
Our old freind DOMDocument does the rest (he says) PHP: DOMDocument - Manual
To work out what’s in the XML files I have found XMLViewer, V4.1.2 useful.
I take that as a no.![]()
I produce a text file of stop sequences served once a week from the zip files within Excel using VBA. I vaguely remember posting about this but nobody seemed terribly interested! As the code runs automatically within a more comprehensive data extraction process the stop sequence files are still being produced.
I have uploaded the current file (produced this week) to
http://www.timetablegraveyard.co.uk/all_stops.txt
Here are the first few lines
267;21_61830;12/08/2023;New file;1;490007705C;O;1;Hammersmith Bus Station;Hammersmith Bus Station;523395;178522
267;21_61830;12/08/2023;New file;2;490008801P;O;2;Livat Hammersmith Shopping Centre;Livat Hammersmith Shopping Centre;523175;178561
267;21_61830;12/08/2023;New file;3;490007711WA;O;3;Hammersmith Town Hall;Hammersmith Town Hall;522778;178543
267;21_61830;12/08/2023;New file;4;490011594W;O;4;Ravenscourt Park Station;Ravenscourt Park Station;522571;178581
267;21_61830;12/08/2023;New file;5;490012533W;O;5;Ravenscourt Park;Ravenscourt Park;522251;178636
267;21_61830;12/08/2023;New file;6;490007272H;O;6;Goldhawk Road (W6);Goldhawk Road (W6);521996;178621
The fields are:-
i) route
ii) operator and pseudo-Service Change Number (pseudo because they no longer match the real SCNs as shown on Working Timetables)
iii) date timetable starts (to be ignored unless in the future)
iv) whether a new file, no change or a metadata revision for an existing stop
v) order in stop sequence
vi) ATCO code (usually 499…)
vii) inbound or outbound
viii) order in stop sequence (again! - I this is done a different way to help track down inconsistencies but I can’t remember off the top of my head)
ix) “CommonName” for stop
x) “Notes” for stop (usually same as CommonName)
xi) easting
xii) northing
This would be easy to import into a database. Because it gives stop sequences there is wholesale duplication of stops but it would be easy enough to ignore unwanted fields and not allowing duplicates. There may also be issues if the stop sequence is corrupted in some way, which happens every few weeks to the odd file. This week’s version is clean however.
I find this very useful.
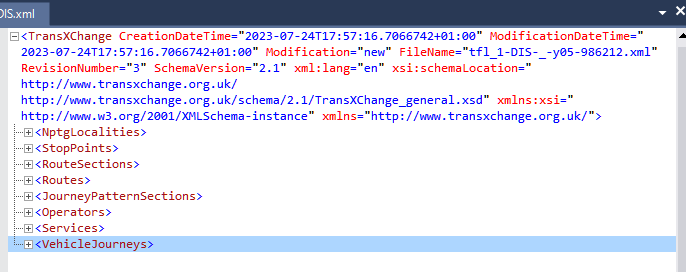
But this is a developer forum…
@mjcarchive
Is the link a one-off post or do you update it regularly?
I have had a quick play with the file and can easily extract and augment the key fields to convert it to my regular routes (sequences) database. They change much more frequently than the basic stop data so a regular update would be really useful. And much easier for me than trying to work out how handle the zip timetables!
Thanks.
PS
Forgot to mention that in column vii every entry is O. I assume they should be I or O?
@misar They should indeed. I’ll check in the next couple of days. I think I can do a deduped version easily enough too, which would just be a stops list. Also it ought to be fairly easy for me to identify new stops within the files and stops no longer there.
@misar I’m not going to produce a file this week as I’d rather get the process properly automated and working properly than do it ad hoc.
My thinking is to provide the stop sequences and stops as Excel rather than text files. In part to get round the issue that it is all too easy to import ATCO codes ending in an E, E2 etc. as involving exponentiation; if I can avoid that by doing an import into Excel myself then nobody else will have the opportunity to accidentally mess it up!
For what it is worth, there is one genuinely new stop this week, 490000169ZA is a new (additional) northbound stop at Old Street Station, served from 19th August (according to the files) by 21 43 76 141 and 214, with N271 probably still to come. Two further stops are reinstated - 490006443Z and 490012727Y - following the end of a southbound diversion on 192 around Edmonton Green.
@mjcarchive I converted your previous .txt file to .csv because I need .csv to use as a database. Also using Excel is essential for manipulating the data. Import the data setting the ATCO column as text instead of general. Providing them as .xlsx avoids the ATCO codes issue but .csv is simple and universal.
If you want to save to .csv for download here are a couple of ways to avoid problems.
- Insert ’ in front of each ATCO code (needs a formula in my version of Excel). That field will then always remain as text even if the .csv is opened directly in Excel. I keep the ’ permanently for safety and strip it out when loading the database into my program but it is easily removed in Excel.
- TfL sometimes insert a comma in a field (e.g. Guy, Earl of Warwick) which in a .csv appears as two fields. Therefore strip out commas before saving as .csv.
PS
Looking at your .txt download again I realised that you were ahead of me and replaced all the commas with _.
Also you mentioned the similarity between the Name and Notes columns. I now see that Names has many commas but Notes omits them, e.g.
Wolsey Avenue_ Walthamstow and Wolsey Avenue Walthamstow
It would be interesting to know what logic at TfL lies behind this!
Top tip: As per the CSV format’s specification, you can wrap strings containing commas with double quotes and it will be treated as a single field. For example, you can do something like:
id,commonName
490G00007611,"Guy, Earl of Warwick"
This should load correctly in most software that can read CSV files (including Excel). And most CSV-writing libraries will automatically surround fields containing commas with double quotes.
1 Like
@LeonByford True, but your .csv downloads do not wrap those fields in double quotes. Also using “Guy, Earl of Warwick” as an example, I noticed that the NaPTAN .csv downloads omit the comma.
Apologies.
I checked back to the original downloads and you do insert double quotes. However, for some .csv uses other than a spreadsheet the policy of omitting commas makes life easier.
@misar and all
Thanks for advice. The file I did last week was essentially a by-product of something I set up a fair time ago and I need to refresh my memory of what it is doing (which is why I’m going to sort out a repeatable and properly documented process rather than just do it again).
My files are generated by Excel VBA. It makes a difference whether you Print or Write to a text file, one of the differences being the way double quotes are used. I may need to switch from one to t’other but that’s easy to change.
The “text treated as number” thing first came up for me when importing TfL’s own stops csv file. It took me longer than it should have to realise that the very large numbers I was getting in Croydon, Sutton and Kingston were bogus and arose from the use of suffices as high as E14!
I haven’t got time right now to refresh the files but I can report that there are two new stops in this week’s Datastore files, namely 490005800PW and 490005800RC. Both appear to be temporary stops for use while Cromwell Road Bus Station in Kingston is closed.
@mjcarchive
No problem. I decided to investigate using the XMLs to prepare a bus sequence CSV and adopted a program approach similar to @briantist rather than the Excel route. My app writes a bus sequence CSV from 781 XML files in about 10 sec but it also revealed some odd stats about the XML files.
I only require a small part of the data in the files and after inspecting a few decided to use RouteLink blocks to obtain the route sequence and StopPoint blocks to augment their stop data. This seems to be a correct assumption for many routes with the number of inbound + outbound entries in the sequence about the same as the number of StopPoints. However, with many other routes the number of sequence entries is far too large and in some cases it is ridiculous. Some stops have two or more XMLs and sometimes only one of those looks anomalous. For example:
Route 71 has 68 StopPoints and 67 RouteLinks.
Route 115 has 77 StopPoints and 113 RouteLinks.
Route 123 has 113 StopPoints and 111 RouteLinks.
Route 123 has 113 StopPoints and 221 RouteLinks.
Route 224 has 63 StopPoints and 2661 RouteLinks.
Route 243 has 122 StopPoints and 235 RouteLinks.
Route 243 has 126 StopPoints and 12099 RouteLinks.
Route 57 has 122 StopPoints and 358 RouteLinks.
Route 57 has 121 StopPoints and 21421 RouteLinks.
The anomaly also explains the enormous variation in XML file size, from 22KB (685) to 30MB (57).
Any thoughts on the reason for the anomalies and, more importantly, how to extract an accurate sequence for every route?
1 Like
I think the idea is that the RouteLinks form a Directed Graph using the nodes.
You would normally expect there to be twice as many RouteLinks as StopPoints - given the bus routes should be running in both directions.
Given that some of the values you are listing for the number of RouteLinks is just short of the square of the StopPoints, I’m going to guess that it’s a software problem that is trying to link every StopPoints to every one one.
@jamesevans may be able to confirm this is an actual malfunction.
My code is generally only looking for StopPoints that are adjacent to rail/tubel/metro station and the importer machine has 128G of RAM, I’ve not seen this complexity as a problem, but the import proceess isn’t the fastest code I’ve ever written.
Does this help?
In fact as I mentioned there should be about the same number of RouteLinks as StopPoints. The StopPoints section lists stops in both directions as they have different NaPTAN ATCO codes. By chance the first few xml files I investigated all complied with that so I was surprised to find the enormous variation.
If the list of StopPoints is always in the correct order that might be a simple way to create a route sequence each way but I have not yet investigated. Your comment about a malfunction is interesting but the two zips I downloaded three weeks apart are about the same size so it would not be a one-off issue.
@briantist @misar
Nice guess, Brian, but I don’t think that is it.
The core of the problem on the 57 file is actually in the RouteSections area. It has no fewer than 364 of them, of which 353 are Fairfield Bus Station - Atkins Road / New Park Road, 8 are Poynders Road / Kings Avenue - Fairfield Bus Station and 2 Merton Abbey / Merton High Street - Fairfield Bus Station. Most routes have 2, one each way.
The knock-on effect is to multiply the number of route links by (in this case) 182.
However, even with these bloated numbers I don’t think this explains the size of the file. OK, I’m working with an Excel input which flattens the data out but the bulk of the data appears to be where it usually is, in the VehicleJourneys and JourneyPatterns sections. We appear to have 1290 individual vehicle journeys, split over 6 different day types, which seems reasonable. This section of the file is greatly expanded by the generous use of the days of non-operation fields which, when flattened out in Excel, increase the apparent number of journeys to more like 7700!
Between them they use 695 different journey patterns, so at least not every journey has a unique pattern. It is a moot point whether this demonstrates the capabilities of scheduling software or what happens when every little difference, however insignificant, in the input historic data is reflected in the output but that is another issue. But I don’t think the numbers are that unusual.
The point is that neither the vehicle journeys nor the journey patterns sections are inflated by (what must be) the error in the RouteSections section. Even if that contained no duplicates the other sections would be just as large and I don’t think the file size would be much less, certainly not by a factor of anything like 10.
I suppose the obvious response to mass duplication in the route links is to dedupe them (within each direction as some route links are used both ways, e g the W9 going round Highlands Village) That is easy enough in Excel (though I am applying it to the journey pattern data, which is meant to duplicate the links) but presumably requires another step in what you are doing. For what it is worth I dedupe using pivot tables rather than “remove duplicates”, because it fits in better with the other work.
Part of me wonders whether I should be looking at the sort of approach that you and Brian are adopting but I am doing a lot more than extracting the stops, including looking for differences. I just leave the Excel VBA running and come back a few hours later!
1 Like
@misar
With regard to the ordering of stop points, they used to be listed in the order implied by the route links (and the journey patterns). This changed to something which looks a bit around the same time lots of other stuff changed (Adiona’s introduction?). No idea why though I have asked a few times on the forum.
Is it easy for you to generate counts of RouteSections as well as RouteLinks and StopPoints? As indicated in my earlier post I think the first of those is the key to this.