In addition to the historical crowding data we released earlier this year, we’ve now released near-real-time crowding data. This calculates busyness at a station level every 5 minutes, as a fraction of the busiest the station has been since data collection began (July 2019). The data covers all tube stations apart from Kensington Olympia, Heathrow Terminal 5 and Willesden Junction. We also consider Monument the same station as Bank for the purposes of crowding so don’t provide separate data for that.
As before, the data is depersonalised and aggregated to protect the privacy of customers.
The request should look like this:
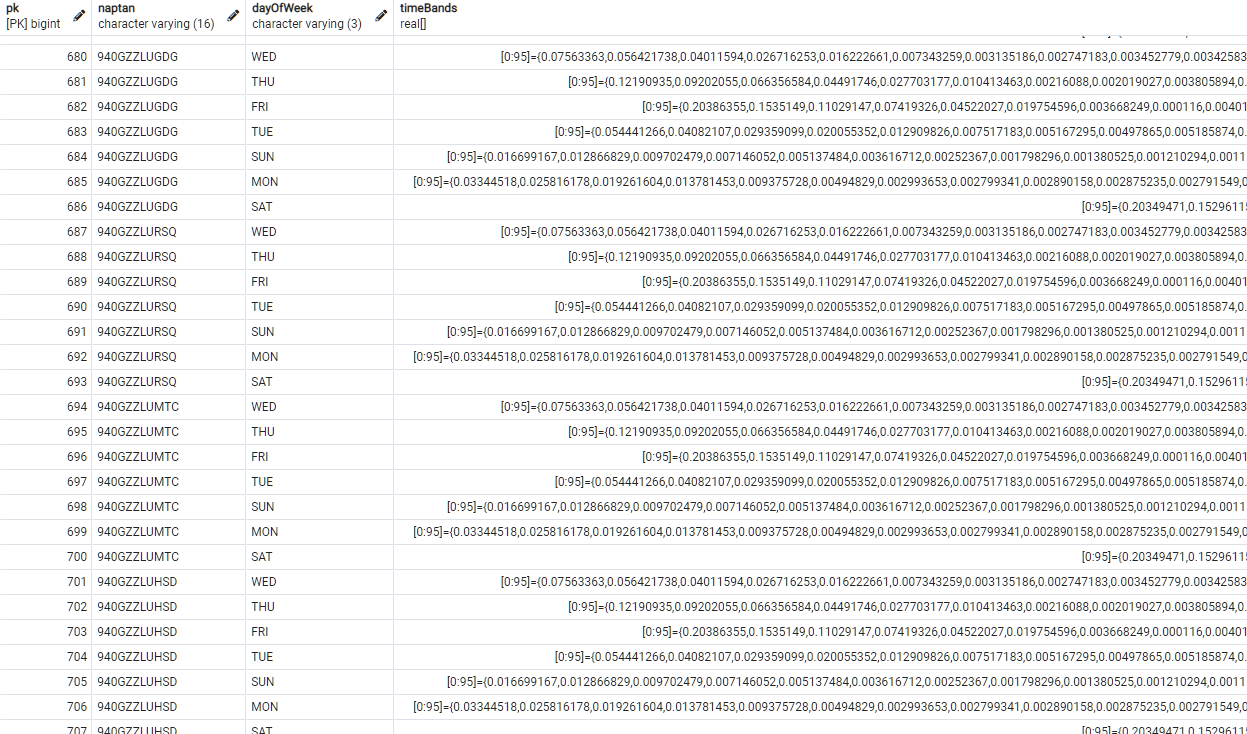
https://api.tfl.gov.uk/crowding/{Naptan}/Live?app_key={ApplicationKey}
{Naptan} should be replaced with the Naptan code of the desired station, and {ApplicationKey} should be replaced with your Application Key for the Unified API (you will need to register to obtain this). It is only possible to get data for one station per request, multiple stations require multiple requests.
The response should look like this:
{“dataAvailable”:true,“percentageOfBaseline”:0.13020833,“timeUtc”:“2021-07-02T11:46:00.000Z”,“timeLocal”:“2021-07-02 12:46:00”}
“percentageOfBaseline” is the latest crowding value, calculated in the last 5 minutes. This is generally between 0 and 1, but can be over 1 in some circumstances. Levels should be described to users in the following way:
Less than 0.4 = quiet
0.4 to 0.7 = busy
Greater than 0.7 = very busy
How TfL is using this data:
To support our demand management campaigns we are using the data to promote to our customers the quieter times at all London Underground stations to help them plan their journeys. This supports our objective of spreading demand across the day and our network.
As restrictive measures ease, it will be especially important to reassure customers and provide them with information that helps them plan journeys at quieter times and make the most of the network’s capacity.
How we would like you to represent the data:
Please focus on the quieter times at the stations, rather than busy times or the peaks.
We hope that customers will use this information to retime their journeys to quieter times and avoid busy times at their origin, interchange or destination stations.
Having access to quieter times at London Underground stations can enhance customer journeys and help reduce crowding.
If you have any questions about the data, please let me know.
Joe